网络知识大杂烩
物理网络设备概念
集线器
工作在物理层,从某一端口收到数据后,将数据发送给其他所有端口,注意这里不涉及任何网络协议,单纯得使用电信号发送数据,由其他已连接设备自行判断是否接收处理数据包
二层交换机
工作在链路层,内部维护一个转发表,转发表包含 MAC 地址与端口的对应关系,根据链路层数据包的目标 MAC 地址,将数据包发送到对应端口;交换机会通过二层以太网帧中的源 MAC 地址进行学习与端口的映射关系,如果当前转发表中不包含数据包的目标 MAC 地址,交换机就会像集线器那样将数据包发送到所有其他端口上
二层交换机只能支持让同一子网/网段之间的设备通讯,跨子网/网段通讯必须依赖路由器/网关
路由器
工作在网络层(IP层),一般用于在不同子网/网段之间作为网关,转发跨子网的数据包;路由器一般还需要支持 NAT 功能,将数据包源 IP 地址修改为自己接口上的 IP 地址
三层交换机
既有二层交换机的功能,也有三层路由器的功能
网桥
工作在链路层,是一种两端口的二层网络设备,用来实现**同一个 IP 网段的不同物理子网段之间的互联互通**。
网桥所沟通的那些机器都是属于同一个IP网段,但是这些机器可能又在物理上分成了多个部分,比如一部分连接到某个集线器,另一部分连接到另外一个集线器,然后使用网桥将两个集线器连接起来
网桥和二层交换机不同,二层交换机内部记录的端口与Mac地址是一对一的,而网桥是一对多的(注:结合上述知识,似乎二层交换机上不适合接入另一个集线器或交换机,如果另一个集线器/交换机上连接有多台设备,那么本二层交换机那个端口对应的Mac地址会经常改动,且会由于总是找不到集线器上某些设备的Mac地址,导致经常广播数据包到所有端口)
这里说的网桥是物理设备,不要与其他概念混淆
- 不要与 linux bridge(brctrl 命令相关)混淆,它的作用更像是一个虚拟交换机,甚至可配置成三层交换机,详见下述
- 不要与 windows 桥接(动词,英文:Bridge Connections)混淆 ,这个东西查不到官方资料,根据网上有限的非权威资料来看,它的作用差不多类似一个虚拟二层交换机,基本可以参考后面详述的 linux bridge 原理
- 测试时发现 windows11 系统下使用 无线网适配器 加 有线网适配器 创建网桥时总是不能成功,提示配置异常
- 这种情况下使用网络共享功能更好,将无线网适配器共享给有线网适配器,再把有线网口连接到交换机或直连其他电脑,其他电脑就可以自动获取到 IP 地址并联网了
- 大概看了下原理,共享模式下本机有线网卡被赋予了另一个网段/子网的 ip 地址,还启动了一个 DHCP 服务端给其他电脑分配那个网段/子网的 IP 地址和网关,网关就是本机有线网卡的 IP 地址,相当于本机是其他电脑的路由器
虚拟网络设备
下面介绍一些与网络相关的虚拟设备,有的是纯虚拟的逻辑上的,有些是根据物理网络设备的功能虚拟出来的,本文提到的大多都是 linux 系统中的虚拟网络设备技术
netns
linux 网络命名空间,是逻辑上的另一个内核网络栈,与系统中默认(无名)命名空间的网络栈是完全隔离的,拥有自己的 netfilter、iptables 规则、路由规则、网络设备/接口也是独立的,甚至连 lo 回环接口都是自己独立的
它可以将网络隔离的特性,可以用来测试网络功能和配置,比如在系统中测试创建的虚拟网络接口
如下命令表示在 ns1 网络命名空间中执行命令 cmd :
ip netns exec ns1 cmd
ip netns exec ns1 ifconfig
可以使用这种命令用来配置 ns1 网络命名空间中网络接口的 IP、网关、甚至在网络指定命名空间中新增虚拟网络接口等等操作,或者任何想要执行的命令
tun 和 tap
前者工作在第三层,后者工作在第二层,在 linux 中 以名为 tun 的内核驱动提供相关功能,也有对应的 windows 实现,主要目标是创建隧道,实现点对点通讯,以及虚拟网卡,后者 tap 常用于作为虚拟机的虚拟网卡,常用的虚拟机网络桥接模式(虚拟机获取到与主机同网段的 IP 地址)就是使用了 tap 实现(以太网桥接)
好文章:
- https://www.junmajinlong.com/virtual/network/all_about_tun_tap/index.html
- https://www.zhaohuabing.com/post/2020-02-24-linux-taptun/
创建 tun/tap 的方法
- 通常使用程序打开 /dev/net/tun 字符设备获取 FD 并使用 FD 调用 ioctl 函数注册虚拟网络接口,程序使用持有的 FD 与虚拟网络接口通讯
- 一般情况下程序关闭 FD 后对应的虚拟网络接口也会自动删除,可以在调用 ioctl 函数时指定要创建持久化的虚拟网络接口
- 使用 iproute2 系列命令的 ip tuntap 可以直接创建持久化的虚拟网络接口
- 程序可以在调用 ioctl 函数时指定要使用已有的/持久化的虚拟网络接口,而不是创建一个新的
使用 tun/tap 的方法
linux tun/tap 驱动程序为应用程序提供了两种交互方式:虚拟网络接口和字符设备 /dev/net/tun
- 写入字符设备 /dev/net/tun 的数据会发送到虚拟网络接口中(再到内核网络栈)
- (从内核网络栈)发送到虚拟网络接口中的数据也会出现在该字符设备上
- 应用程序 <--> Socket API <--> 内核网络栈 <--> [可能经过网络 <--> 内核网络栈] <--> tun/tap 虚拟网络接口 <--> 字符设备 <--> 应用程序
- 数据包在 内核网络栈 中会判断数据包目标,可能会将数据包送往真实物理网口,进而发送到网络上
- 应用程序可以通过标准的 Socket API 向 tun/tap 接口发送 IP 数据包,就好像对一个真实的网卡进行操作一样。除了应用程序以外,操作系统也会根据 TCP/IP 协议栈的处理向 tun/tap 接口发送 IP 数据包或者以太网数据包,例如 ARP 或者 ICMP 数据包。tun/tap 驱动程序会将 tun/tap 接口收到的数据包原样写入到 /dev/net/tun 字符设备上,处理 tun/tap 数据的应用程序如 VPN 程序可以从该设备上读取到数据包,以进行相应处理
- 应用程序也可以通过 /dev/net/tun 字符设备写入数据包,这种情况下该字符设备上写入的数据包会被发送到 tun/tap 虚拟接口上,进入操作系统的 TCP/IP 协议栈进行相应处理,就像从物理网卡进入操作系统的数据一样
tunnel 隧道
与 tun/tap 名字看起来很像,但原理上不同,tun/tap 只工作在本机,但 tunnel 一般应用于隔着网络的两台机器之间,不过可以基于 tun/tap 技术去实现 tunnel
好文推荐:
- https://lartc.org/howto/lartc.tunnel.html
- https://www.cloudflare.com/zh-cn/learning/network-layer/what-is-tunneling/
- https://www.cnblogs.com/bakari/p/10564347.html
简言之,隧道技术可用来传输本无法/不愿直接传输的数据
隧道中真正传输的一般都是被二次封装的数据帧,即原始/目标网络协议数据被另一种网络协议封装后使用隧道进行传输,原始/目标网络协议可以是 OSI 网络分层中的任何一种协议
应用场景:
- 比如某个防火墙禁止使用某些网络协议,此时就可以将目标网络协议封装进防火墙允许的网络协议中,这样就可以穿过防火墙传输数据了
- 比如要把 ipv6 协议帧发送到一个目的地,但中间需要经过的网络/路由不支持 ipv6,这时就可以使用 ipv4 协议帧封装 ipv6 协议帧,然后通过网络传输到目的地,再有目的地程序解包出 ipv6 数据,进而交由网络栈进一步处理 ipv6 数据,这个隧道就是 ipip 系列类型的隧道
有多种耳熟能详的协议/技术其实都应用了 tunnel 的技术,常用的有:
- IP in IP(内核内置支持)
- GRE(内核内置支持)https://www.cloudflare.com/zh-cn/learning/network-layer/what-is-gre-tunneling/
- SSH tunnel
- IPsec
- L2TP
- PPTP
- PPPoE
- SOCKS
上述有多种协议类型都应用于了 VPN 的通讯
注意,上述隧道协议有些是 linux 默认就支持的(通过内置的内核驱动),这些协议的隧道使用 ip tunnel 命令就可以直接创建,其他协议可能需要安装对应的软件或驱动才能使用,比如 ip tunnel 命令就无法创建 SSH tunnel
可以使用 iproute2 系列命令中的 ip tunnel 命令创建和管理 linux 内核支持的 tunnel 网络接口,这样创建出来的隧道是直接可以工作的,不需要再依赖第三方程序做处理
ip tunnel add NAME mode MODE remote ADDR local ADDR
注意:其中 remote/local 选项是设置的隧道中协议包数据的 外层 dst/src 地址,也就是对原始数据包再封装时使用的地址,一般使用两个网络各自的网关/路由地址
注意:tunnel 添加完毕后还需要设置路由,让目标数据包走 tunnel 对应的网络接口,这样才能让 tunnel 对目标数据包再封包然后发出去
其中 mode 参数常用选项如下:
- mode ipip:
- IP in IP 隧道模式是一种简单的隧道模式,它在两个 IP 数据包之间添加一个额外的 IP 头。源 IP 是隧道发起者的 IP 地址,目标 IP 是隧道终点的 IP 地址。
- 这种模式通常用于创建跨越公共 Internet 的隧道,用于连接不同网络之间的 IPv4 子网。
- mode gre:
- 通用路由封装(Generic Routing Encapsulation,GRE)隧道模式是一种灵活的隧道模式,它允许将任何类型的网络协议封装在 GRE 头中传输。
- GRE 隧道通常用于建立点对点或点到多点的隧道,允许将不同类型的网络连接在一起,如 IPv4、IPv6、以太网等。
- mode sit:
- 6to4 隧道(IPv6 over IPv4)模式,也称为站点本地隧道(Site-to-Site Tunneling),用于在 IPv4 网络上传输 IPv6 数据。
- 在这种模式下,IPv6 数据包被封装在 IPv4 数据包中,通过 IPv4 网络传输,并在隧道的两端进行解封装。
- mode ip6ip6:
- IPv6 over IPv6 隧道模式是一种用于在 IPv6 网络上传输 IPv6 数据包的隧道模式。它类似于 mode ipip,但是用于 IPv6 数据包。
- 这种模式通常用于连接两个 IPv6 网络,允许 IPv6 数据在不同的 IPv6 子网之间进行传输。
- mode ip6gre:
- IPv6 over GRE 隧道模式类似于 mode ip6ip6,但是使用 GRE 封装 IPv6 数据包进行传输。
- 这种模式提供了与 GRE 隧道类似的灵活性,但用于 IPv6 数据包的传输。
一个小提示:
删除 tunl0 虚拟网络接口失败:delete tunnel "tunl0" failed: Operation not permitted
这是因为 tunl0 是 ipip 内核模块初始化时创建的,不能直接删除,需要卸载 ipip 内核模块,卸载后自动就删除了
linux bridge 网桥
可以让 linux 系统作为一个虚拟三层交换机,注意是三层带路由功能的交换机,为其他同子网的机器之间转发数据包(交换机功能),或者作为其他机器的网关访问不同的子网/外网(路由器功能)
下面我们做些准备工作来测试下 linux bridge 的功能,分别测试 二层交换机的转发功能 和 三层交换机的路由功能
创建 bridge
要创建 bridge 需要使用 brctl 命令 brctl addbr br0,此时系统上就创建了名为 br0 的网络接口,同时虚拟交换机也创建好了
有多种命令可以创建和管理网桥,比如也可以使用 iproute2 系列命令中的 ip 和 bridge 命令,但 brctl 更简短,后面就以 brctl 为例了
为了便于理解,这里类比物理交换机来看看刚刚创建的的虚拟交换机:
- 物理交换机上有各种端口(网线插槽),每个端口都有自己的名字,一般是数字序号 1 2 3 4...
- 虚拟交换机从使用层面来看没有端口的概念,但我们可以将网络接口类比到虚拟交换机的端口,那么网络接口名就是端口名
- 当将一个网络接口添加到 bridge 上时,就隐式的为虚拟交换机增加了一个与网络接口同名的端口
- 就上面的 brctl addbr br0 命令来说,系统就类似于自动做了如下事情:
- 创建虚拟交换机(名为 br0,稍后解释此名称来源,注意 br0 这个名称会用到多个不同的虚拟事物上)
- 为虚拟交换机创建了默认端口 br0
- 在 linux 系统中创建了虚拟网络接口 br0
- 将这个网络接口 br0(通过一根虚拟网线)连接到虚拟交换机同名的端口 br0 上,类比到物理世界,这相当于使用一根网线把这个 linux 主机(的 br0 网口)与一个交换机连了起来(注意,这里要把虚拟交换机与 linux 系统看作两个部分才好理解)
- 由于支持通过 brctl 命令创建多个独立的虚拟交换机,那么虚拟交换机就需要有 ID/名字以便区分,所以系统就把刚刚创建好的虚拟交换机同样命名为了与默认端口和默认虚拟网络接口都同名的 br0
- 到此就彻底顺下来了:一个名为 br0 的交换机上默认有一个名为 br0 的端口,连接了 linux 主机上名为 br0 的网口
注意:这些都是概念性的,为了便于理解而类比出来的,当使用 brctl show 命令列出所有 bridge 时,其实看不到这个默认的 br0 接口,所以此时 brctl show 命令的输出只能看到一个名为 br0 的 bridge 和空的 interfaces
在 bridge 上添加接口
添加系统中的物理网络接口 eth1 到 bridge:brctl addif br0 eth1,这相当于为虚拟交换机创建了名为 eth1 的端口,并让物理网口 eth1 的插槽作为此端口的插槽
注意物理网络接口 eth1 仍可以独立使用,可以为其配置 IP 地址、网关等等,此时如果有一个机器连接了 eth1,并 ping eth1 上配置的 IP 地址,是能够 ping 通的
添加系统中的物理网络接口 eth2 到 bridge:brctl addif br0 eth2,同理参考上面 eth1 的解释
此时虚拟交换机的状态为有三个端口:
- 默认端口 br0 已经被使用,被用来连接了 linux 主机
- 还有两个空闲的端口 eth1 和 eth2
测试虚拟交换机二层功能
接下来我们测试此虚拟交换机的二层交换机功能是否能正常工作
首先说明我们目前仅测试虚拟交换机的二层包转发功能,所以不论 br0 eth1 eth2 网络接口上是否配置了 IP 地址以及配置的是什么都无所谓
找另外一台主机 A,配置其 IP 地址为 192.168.0.101,再使用网线连接它与 linux 主机的 eth1 物理网口
找另外一台主机 B,配置其 IP 地址为 192.168.0.102,再使用网线连接它与 linux 主机的 eth2 物理网口
注意目前主机 A 和 B 的 IP 地址必须是同网段/子网的,因为二层交换机只处理同网段/子网的数据,网段/子网间通讯需要三层的 IP 数据包路由功能,也就是说还需要一个路由器,并且还需要在主机 A 和 B 上将网关配置成路由器的 IP,以便跨网段/子网的数据包可以从主机 A 和 B 发送到路由器上,再由路由器进一步转发(路由器路由还涉及 NAT/SNAT),我们创建的虚拟交换机虽然是三层交换机,但还需要配置各个部分的 IP、网关、路由规则才能真正用起来三层的路由功能
配置 linux 主机允许转发数据包:
- 别忘了启用 br0 网口:ip link set br0 up
- sysctl -w net.ipv4.ip_forward=1
- iptables -I FORWARD -i br0 -j ACCEPT
bridge 上的数据是否通过 netfilter(iptables/arptables)是可配置的,配置参数可以通过 sysctl 命令修改,与上面修改 net.ipv4.ip_forward 一样,相关的配置项有:
- net.bridge.bridge-nf-call-iptables
- net.bridge.bridge-nf-call-ip6tables
- net.bridge.bridge-nf-call-arptables
现在我们在主机 A 和 B 上 ping 对方的 IP 就可以发现是通的,这就说明虚拟交换机的二层交换机功能已经正常工作了
当前拓扑:主机 A(192.168.0.101) <--> linux 主机(二层交换机) <--> 主机 B(192.168.0.102)
测试虚拟交换机三层功能
接下来我们测试此虚拟交换机的三层路由功能是否能正常工作
保持当前物理网线连接状态不动
首先试试将主机 B 的 IP 地址修改为 192.168.1.102,然后在主机 A 和 B 上互相 ping 对方,会发现不通,这是正常的,因为目前整个网络拓扑中还没有进行三层的路由配置,执行 ping 命令时的数据包根本不会发送的 linux 主机上,甚至都没有封包出 ping 命令的 ICMP 协议数据包,因为在这之前需要先获取对方 MAC 地址时,这一步的 ARP 请求数据包都不会发出去,内核网络栈直接就把 ARP 请求数据包丢弃了
当已经将物理网口 eth1 和 eth2 添加到虚拟交换机上时,这两个网口上就可以不配置任何 IP 地址、网关了,原本这两个网口需要做的事情,都可以放到 br0 虚拟网口上实现(一个网口可以配置多个 IP 地址)
对 linux 主机虚拟交换机进行网络配置,以便可以正常跨网段/子网路由数据包:
- 首先删除 eth1 和 eth2 相关的 IP 配置和路由规则(相关命令为 ip addr 和 ip route,具体命令不再详述)
- 在 br0 虚拟网口上配置两个 IP 地址:192.168.0.200 和 192.168.1.200(注意:分别属于主机 A 和 主机 B 的网段/子网),参考命令:
- ip addr add 192.168.0.200/24 dev br0
- ip addr add 192.168.1.200/24 dev br0
- 配置 IP 地址时一般会配置相关的路由,比如 br0 目前就会有如下两条路由,使用 ip route 命令查看:
- 192.168.0.0/24 dev br0 proto kernel scope link src 192.168.0.200
- 192.168.1.0/24 dev br0 proto kernel scope link src 192.168.1.200
- 没有的话可以使用命令添加:
- ip route add 192.168.0.0/24 dev br0 src 192.168.0.200
- 这表示访问网段/子网 192.168.0.0/24 的任一 IP 时,从 br0 发送数据包,且源 IP 地址为 192.168.0.200
- ip route add 192.168.1.0/24 dev br0 src 192.168.1.200
- 这表示访问网段/子网 192.168.1.0/24 的任一 IP 时,从 br0 发送数据包,且源 IP 地址为 192.168.1.200
- ip route add 192.168.0.0/24 dev br0 src 192.168.0.200
- 还需要配置路由的 SNAT,将数据包的源 IP 地址修改为 br0 的 IP 地址,否则即便数据包到达目标,目标内核网络栈发现源 IP 地址与自己不在同一个网段/子网,也不会进行处理,而是直接丢弃,使用如下命令:
- iptables -t nat -I POSTROUTING -o br0 -d 192.168.1.0/24 -j SNAT --to 192.168.1.200
- 这表示在从 br0 网络接口向网段/子网 192.168.1.0/24 的任一 IP 发送 IP 数据时,修改数据包的源 IP 地址为本机的 192.168.1.200
- iptables -t nat -I POSTROUTING -o br0 -d 192.168.0.0/24 -j SNAT --to 192.168.0.200
- 原理同上
- 此时虚拟交换机的三层路由功能就准备好了, linux 主机也就变身成了路由器,可在主机 A 和 B 之间路由数据包
接下来在主机 A 上配置发往主机 B 所在网段/子网的数据包要走的网关/路由器 IP 地址为 linux br0 网口的 IP 地址:
- ip route add 192.168.1.0/24 via 192.168.0.200 dev eth1
- 这表示主机 A 访问主机 B 所在网段/子网 192.168.1.0/24 的任一 IP 时,需要先把数据包从主机 A 的 eth1 网口发送给网关/路由器 192.168.0.200,由路由器进一步转发数据包
然后在主机 B 上如法炮制: - ip route add 192.168.0.0/24 via 192.168.1.200 dev eth1
- 这表示主机 B 访问主机 A 所在网段/子网 192.168.0.0/24 的任一 IP 时,需要先把数据包从主机 B 的 eth1 网口发送给网关/路由器 192.168.1.200,由路由器进一步转发数据包
到此配置完毕,在主机 A 上 ping 主机 B 的 IP 192.168.1.102 就可以通了,反之亦然
数据转发/路由相关
OSI 分层网络模型关键层:
- 链路层,常见 以太网帧协议
- 网络层,常见 IP 协议
- 传输层,常见 TCP/UDP 协议
ARP 协议用于获取某个 IP 对应的 MAC 地址,以便可以组包以太网帧
注意,二层交换机并不使用 ARP 协议获取并学习 MAC 地址
同子网转发具体过程
同网段/子网转发一般由交换机负责,数据不会到路由器
从一个数据包的 IP 层开始分析:
- A 要向同一个子网中的 B 发送数据,A 将数据封装进 IP 协议帧
- A 根据 B 的 IP 与自己的子网掩码计算后发现 B 与自己在同一个网络/子网中
- A 查看自己是否有 B 的 MAC 地址?
- 有的话将 IP 协议帧封装进以太网协议帧然后发出去,发到交换机或直接到 B(A B 直连的话)
- 没有的话,发出 ARP 请求询问 B 的 MAC 地址,发到交换机或直接到 B(A B 直连的话)
- 交换机将 ARP 请求发送到每一个已连接设备的端口
- B 收到 ARP 请求后查看是要找自己,就发出 ARP 回复
- 获取不到 B 的 MAC 地址则放弃
- 获取到 B 的 MAC 地址后将 IP 协议帧封装进以太网协议帧然后发出去,发到交换机或直接到 B(A B 直连的话)
跨子网转发具体过程
跨网段/子网转发一般由路由器负责,数据会先通过交换机到达路由器,然后路由器再转发到下一跳路由器(如果有的话),直到某个路由器发现这个数据包的目标 IP 地址就在自己负责的某个网段/子网范围中,此路由器就把数据包发送给它的交换机,再由交换机发送到目标设备所在端口
从一个数据包的 IP 层开始分析:
- A 要向另一个子网中的 B 发送数据,A 将数据封装进 IP 协议帧
- A 根据 B 的 IP 与自己的子网掩码计算后发现 B 与自己不在同一个网络/子网中
- A 是否配置有网关/路由器?(注意:这里不会直接发出 ARP 请求询问 B 的 MAC 地址,所以目前不会有任何数据发到交换机上)
- 没有的话则放弃
- 有的话,发出 ARP 请求询问网关/路由器的 MAC 地址,发到交换机或直接到网关/路由器(A 与 网关/路由器 直连的话)
- 获取不到网关/路由器的 MAC 地址则放弃
- 获取到网关/路由器的 MAC 地址后,使用此 MAC 地址(注意不是 B 的 MAC 地址)将 IP 协议帧封装进以太网协议帧然后发出去,发到交换机或直接到网关/路由器(A 与 网关/路由器 直连的话)
- 路由器收到发给自己的以太网帧后解包,发现目标 IP 是 B 的 IP 地址
- 根据路由表判断是否能找到下一跳路由器的 IP 地址?(路由表构建除了静态表还有动态学习的动态表,涉及到动态路由协议)
- 不能的话则放弃
- 能的话根据下一跳路由器的 IP 地址找到其 MAC 地址(涉及到 ARP 协议),再次封装以太网帧并发出
- 继续路由至下一跳路由器
- ......
- 数据包终于路由至 B 所在子网的网关/路由器,此路由器知道数据包的目标 IP 地址就在自己的子网内
- B 的网关/路由器把数据发送到 B 所在的交换机中,最终数据到达 B
- 注:路由过程中涉及到 NAT,路由器会修改源 IP 地址为自己的 IP 地址,以便隐藏内部 IP,同时也避免 B 拿着源 IP 地址发回数据时找不到 A,因为 B 的网络或临近网络中可能有另一个与 A 使用相同 IP 地址的设备
调试工具
- tcpdump:linux 命令行,捕获指定条件下的数据
- windump:windows 命令行,tcpdump 的 windows 版本,来自 WinPcap
- wireshark:GUI,捕获指定条件下的数据
- scapy:命令行,python,跨平台,全能,支持构造和发送任意协议数据包,支持加载/回放 pcap 文件,也支持捕获数据(sniff 函数)
FAQ
- 分属不同子网/网段的两台设备连接到同一个交换机,它们之间可以通讯吗?
- 答案:不能,不同子网/网段之间通讯必须依赖路由器
- 具体解释:从 A 向 B 发送数据包时,数据包将包含目标 IP 地址,那么 A 知道其子网上的 IP 地址范围(通过子网划分),因此 A 将知道计算机 B 不在其网络上,A 知道要与其网络外部的任何目标进行通信,它需要将数据包发送到某个路由器/网关(而不是交换机),所以它会执行 ARP 并获取路由器的 MAC,但如果它没有连接到任何路由器/网关(可能未配置网关或路由器/网关异常),那么这里什么也不会做(注意并不会将数据包发送到交换机)
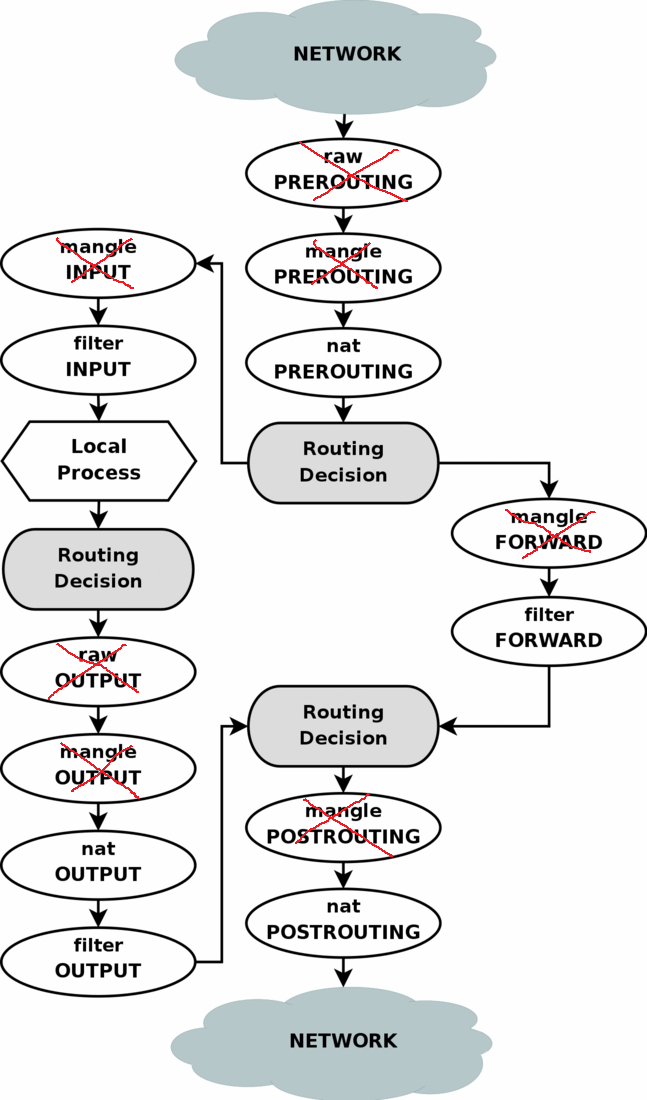
iptables 原理图
在大多数使用情况下都不会用到 raw,mangle 和 security 表。下图简要描述了网络数据包通过 iptables 的过程: